Gradient Tape and TensorFlow 2.0 to train Keras Model
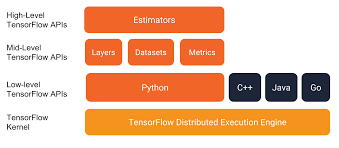
Tensorflow is an end-to-end open-source machine learning platform for everyone. It has a comprehensive, flexible ecosystem of tools, libraries, and community resources that lets researchers push the state-of-the-art in ML, and developers easily build and deploy ML-powered applications.


whereas, With over 375,000 individual users as of early 2020, Keras has strong adoption across both the industry and the research community. Together with TensorFlow 2.0, Keras has more adoption than any other deep learning solution — in every vertical. You are already constantly interacting with features built with Keras — it is in use at Netflix, Uber, Yelp, Instacart, Zocdoc, Square, and many others. It is especially popular among startups that place deep learning at the core of their products. Keras & TensorFlow 2.0 are also a favorite among researchers, coming in #1 in terms of mentions in scientific papers indexed by Google Scholar. Keras has also been adopted by researchers at large scientific organizations, such as CERN and NASA. Tensorflow can be used by GradientTape. The function to create custom training loops to train Keras models.

GradientTape is a brand new function in TensorFlow 2.0 and that it can be used for automatic differentiation and writing custom training loops. GradientTape can be used to write custom training loops (both for Keras models and models implemented in “pure” TensorFlow)


One of the largest criticisms of the TensorFlow 1.x low-level API, as well as the Keras high-level API, was that it made it very challenging for deep learning researchers to write custom training loops that could:
- Customize the data batching process
- Handle multiple inputs and/or outputs with different spatial dimensions
- Utilize a custom loss function
- Access gradients for specific layers and update them in a unique manner
That’s not to say you couldn’t create custom training loops with Keras and TensorFlow 1.x. You could; it was just a bit of a bear and ultimately one of the driving reasons why some researchers ended up switching to PyTorch — they simply didn’t want the headache anymore and desired a better way to implement their training procedures.
That all changed in TensorFlow 2.0.
With the TensorFlow 2.0 release, we now have the GradientTape function, which makes it easier than ever to write custom training loops for both TensorFlow and Keras models, thanks to automatic differentiation. Whether you’re a deep learning practitioner or a seasoned researcher, you should learn how to use the GradientTape function — it allows you to create custom training loops for models implemented in Keras’ easy-to-use API, giving you the best of both worlds. You just can’t beat that combination. Using TensorFlow and GradientTape to train a Keras model
IMPLEMENTATION OF GRADIENT TAPE
GradientTape function to implement such a custom training loop. Finally, we’ll use our custom training loop to train a Keras model and check results.
GradientTape: What is automatic differentiation?


GradientTape to train a Keras model requires conceptual knowledge of automatic differentiation — a set of techniques to automatically compute the derivative of a function by applying the chain rule. Automatic differentiation (also called computational differentiation) refers to a set of techniques that can automatically compute the derivative of a function by repeatedly applying the chain rule. Wikipedia’s excellent article on automatic differentiation:
Automatic differentiation exploits the fact that every computer program, no matter how complicated, executes a sequence of elementary arithmetic operations (addition, subtraction, multiplication, division, etc.) and elementary functions (exp, log, sin, cos, etc.).By applying the chain rule repeatedly to these operations, derivatives of arbitrary order can be computed automatically, accurately to working precision, and using at most a small constant factor more arithmetic operations than the original program.
Unlike classical differentiation algorithms such as symbolic differentiation (which is inefficient) and numerical differentiation (which is prone to discretization and round-off errors), automatic differentiation is fast and efficient, and best of all, it can compute partial derivatives with respect to many inputs (which is exactly what we need when applying gradient descent to train our models). To learn more about the inner-workings of automatic differentiation algorithms, I would recommend reviewing the slides to this University of Toronto lecture as well as working through this example by Chi-Feng Wang.
4 components of a deep neural network training loop with TensorFlow, GradientTape, and Keras
When implementing custom training loops with Keras and TensorFlow, you to need to define, at a bare minimum, four components:
- Component 1: The model architecture
- Component 2: The loss function used when computing the model loss
- Component 3: The optimizer used to update the model weights
- Component 4: The step function that encapsulates the forward and backward pass of the network
Each of these components could be simple or complex, but at a bare minimum, you will need all four when creating a custom training loop for your own models. Once you’ve defined them, GradientTape takes care of the rest.
Our Python script will use GradientTape to train a custom CNN on the MNIST dataset (TensorFlow will download MNIST if you don’t have it already cached on your system).
Implementing the TensorFlow and GradientTape training script
Let’s learn how to use TensorFlow’s GradientTape function to implement a custom training loop to train a Keras model.
Open up the gradient_tape_example.py file in the GitHub link
Using TensorFlow and GradientTape to train a Keras model
Training our Keras model with TensorFlow and GradientTape
From there, open up a terminal and execute the following command
$ time python gttf.py
Our model is obtaining 99.27% accuracy on our testing set after we trained it using our GradientTape custom training procedure.
At a bare minimum, you need to define the four components of a training procedure including the model architecture, loss function, optimizer, and step-function — each of these components could be incredibly simple or extremely complex, but each of them must be present.
BIO: Arpit Bhushan Sharma is an Electrical and Electronics Engineer and pursuing his Bachelor of technology from the KIET Group of Institutions, Ghaziabad. He has a little bit of experience in python and machine learning and wants to make his career in Machine Learning. He loves to write technical articles on various aspects of data science on the Medium platform and Blogger Platform.
For Contacting:E-Mail: bhushansharmaarpit@gmail.com
Blogger: arpit-ml.blogspot.com
Reference:



Comments
Post a Comment