Hyperparameter Tuning in Python
One of the easiest ways to get the last juice out of the models is to pick the right hyperparameters for machine learning or deep learning models. I will show you in this article some of the best ways to do hyperparameter tuning available today (in 2021)
Difference between parameter and hyper-parameters?
- Parameters of the model: These are the parameters calculated on the given dataset by the model. The weights of a deep neural network, for instance.
- Hyperparameters of Models: these are the parameters where the data model cannot predict. This is used for calculating the parameters of the model. For starters, in deep neural networks the learning rate.
Why Hyper-parameter tuning is more important?
The tuning technique is used to estimate the best hyperparameter combination that helps the algorithm to optimise the efficiency of the model. The proper hyperparameter combination is the only way to achieve the full value from the models.
How to Choose Hyper-parameters?
Methods of Hyper-Parameter Tuning
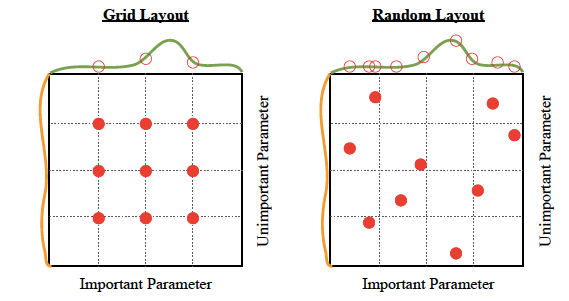
- Random Search: We construct a grid of potential hyperparameter values using the random search technique. Each iteration attempts a random mix of hyperparameters, tracks the output of the grid and eventually returns the best performing combination of the hyperparameters.
- Grid Search: We construct a grid of potential hyperparameter values in the grid search process. Each iteration attempts in a particular order to combine hyperparameters. It adapts to all possible hyperparameter configurations and reports the efficiency of the model. Finally, for the optimal hyperparameters, the best model returns.
- Bayesian Optimization: The optimisation challenge is to tune and locate the correct hyperparameters for your model. By adjusting model parameters, we wish to minimise the loss function of our model. In a minimal number of moves, Bayesian optimism helps one find the minimum point. Bayesian optimization also uses a buying feature which guides the sampling in areas where the best observation is likely to improve on the present one.
- Tree-structured Parzen estimators (TPE): The principle of optimising Tree-based Parzen is like optimising Bayesian. The hyperparameter values of the TPE models P(x|y) and P instead of finding the values of p(y|x) where y is the minimised function (e.g., validated loss) and x (y). One of the major limitations of tree-structured Parzen estimators is that the hyperparameters do not map interactions. Thus TPE performs very well and was checked in most fields. This works very well in practice.
Hyperparameter tuning algorithms
- Hyperband: Hyperband is a random search variant, but with some discovery, philosophy to find the right time assignment for each setup. For more information, please see this research article.
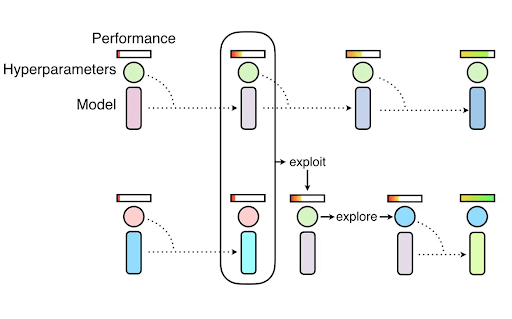
- Population-based training (PBT): This methodology is the hybrid of two search techniques most widely used, namely random search and manual tuning for neural network models. PBT begins teaching several neural networks with random hyperparameters in parallel. However, these networks are not completely separate. The data from the rest of the population is used to optimise hyperparameters and to define the hyperparameter value to attempt. For more information on PBT, please review this post.
- Bayesian Optimization and HyperBand(BOHB): BOHB (Bayesian Optimization and HyperBand) mixes the Hyperband algorithm and Bayesian optimization.
Important tools & Libraries for Hyper-Parameter Tuning
Some of the best Hyperparameter Optimization libraries are:
- Scikit-learn (grid search, random search)
- Hyperopt
- Scikit-Optimize
- Optuna
- Ray.tune
Scikit learn
Scikit-learn has implementations for grid search and random search and is a good place to start if you are building models with sklearn. For both of those methods, sci-kit-learn trains and evaluates a model in a k fold cross-validation setting over various parameter choices and returns the best model.
Specifically:
- Random search: with
randomsearchcvruns the search over some number of random parameter combinations - Grid search:
gridsearchcvruns the search over all parameter sets in the grid
Tuning models with scikit-learn is a good start but there are better options out there and they often have random search strategy anyway.
Hyperopt
Scikit-optimize
Optuna
In order to decide the promising region for maximising the hyperparameter, Optuna uses a historical record of trails and thus finds optimum parameter within a minimum time. It has a cutting mechanism that prevents promising pathways in the early stages of training automatically. Four of the most important characteristics of optuna are:
- Architecture lightweight, scalable and platform-agnostic
- Check spaces Pythonic
- Effective algorithms for optimization
- Simple to parallel
- Quick visualisation
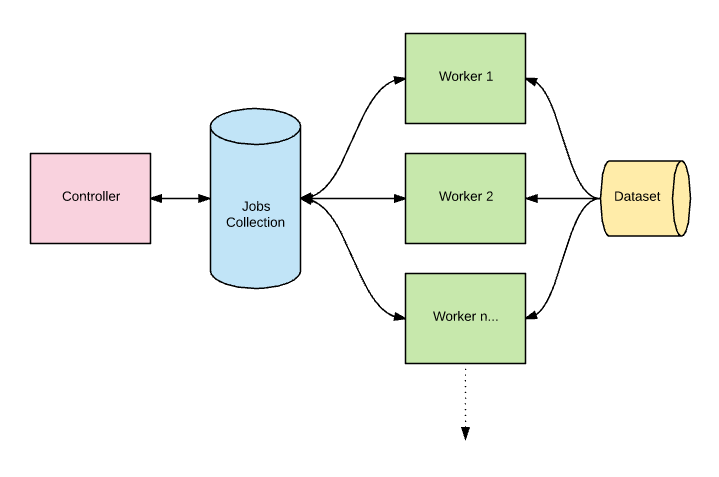
Ray Tune
RayTune is a common choice of experiments and tuning in every scale for hyperparameters. Ray uses the strength of distributed computation to speed up the optimization of the hyperparameters and has a scaling algorithm for a variety of state of the art. Any of the main characteristics of ray tuning are:
- Asynchronous optimization spread by Ray from the box. distributed It’s quick to scale.
- SOTA algorithms like ASHA, BOHB and population-based workouts were supported.
- Supports MLflow and Tensorboard.
- Supports a wide range of frames, such as sklearn, xgboost, TensorFlow and PyTorch.
Keras Tuner
Keras Tuner is a library that allows you to select the right collection of hyperparameters for TensorFlow. In addition to model architecture, when you create a model for tuning hyperparameters, you also describe the search space of the hyperparameter.
A hyper model is called the model you set up for the tuning of hyperparameters. Two approaches help you to describe a hypermodel:
- By using a blueprint building function
- By splitting the Keras Tuner API HyperModel class
You can also use HyperXception and HyperResNet for machine viewing purposes, two predefined HyperModel groups.
Hyper Parameter Tuning Resources and Examples
Random forest
- Understanding Random forest hyperparameters
- Bayesian hyperparameter tuning for random forest
- Random forest tuning using grid search
XGBoost
- XGBoost hyperparameters tuning python
- XGBoost hyperparameters tuning in R
- XGBoost hyperparameter using hyperopt
- Optuna hyperparameter tuning example
LightGBM
- Understanding LightGBM parameters
- LightGBM hyperparameter tuning example
- Optuna for LIghtGBM hyperparameter tuning
Catboost
Keras
- Hyperparameter tuning using Keras- tuner example
- Keras CNN hyperparameter tuning
- How to use Keras models in scikit-learn grid search
Pytorch
About the Author: Arpit Bhushan Sharma (B.Tech, 2016–2020) Electrical & Electronics Engineering, Dr APJ Abdul Kalam Technical University, Lucknow | Patent Analyst — Lakshmikumaran & Sridharan Attorney | Microsoft Student Partner (Beta)| Student Member R10 IEEE | Student Member PELS/PES | E-mail: bhushansharmaarpit@gmail.com
If you really like the article, please do the honour by comment and sharing (citation) for motivating me.


Comments
Post a Comment